Estimating Memory Consumption and Runtime
The presence of the max_bond_dim and max_krylov_dim config parameters means an upper bound on memory consumption and the complexity of the time evolving algorithm can be estimated. By limiting the max_bond_dim of a simulation to make it fit in the available hardware memory, it can be guaranteed to run for arbitrary times for an arbitrary number of qubits. Of course, the sources of error described on the error page imply that limiting the memory consumption of the program will negatively impact the quality of the results once a certain threshold is exceeded. The page in this link, for example, outlines a case study to determine whether emulation results are accurate.
Estimating the memory consumption of a simulation
Section titled “Estimating the memory consumption of a simulation”In this section we outline how to estimate the memory consumption of a simulation, for a given max_bond_dim, a Krylov subspace of size max_krylov_dim, and for being the number of qubits to be simulated.
There are four contributions to the peak memory consumption of emu-mps that will be discussed in the next sections:
- the state
- the baths
- the Krylov space
- temporary tensors
Contribution from the state
Section titled “Contribution from the state”The quantum state is stored in MPS format (see here). At worst, the bond dimensions of the tensors in an MPS grow exponentially inwards as
in which case an MPS will take more memory than a state vector. Let denote the value of max_bond_dim.
When , the bond dimensions in the center all cap at that fixed value of max_bond_dim. Since each tensor in the MPS has 2 bonds of size at most , and a physical index of size , where each element in the tensor takes bytes (2 8-byte floats to store a complex number), the memory consumption of the state reads
Note that this is a strict over-estimation because the outer bonds in the MPS will be much smaller than .
Contribution from the baths
Section titled “Contribution from the baths”For TDVP, for each qubit a left and a right bath tensor is stored. The bath tensors are used to compute an effective interaction between the 2-qubit subsystem being evolved, and the rest of the system (see here). Each of them has 3 indices. Two of them will have a size that depends on the state that is evolved, here upper bounded by the maximum allowed value for the bond dimension. For the third, the size will depend on the interaction type. In concrete, for each qubit, will be the bond dimension of the MPO representation of the Hamiltonian. In summary, for the Rydberg Hamiltonian we expect that , and for the XY Hamiltonian that , where in both cases for the bath associated with the qubit . The computation is slightly involved, but summing all the contributions leads to a total memory occupation of the baths:
Note that the baths take up more memory than the state, always, and potentially much more. Furthermore, just as for the state this is a strict over-estimation, because it assumes all the bonds in the state are of size .
Contribution from the Krylov space
Section titled “Contribution from the Krylov space”The remainder of the memory consumption is to compute the time-evolution of qubit pairs in TDVP. This is done by contracting 2 tensors from the MPS together into a single 2-qubit tensor, and time-evolving it by applying an effective Hamiltonian constructed from the baths and the Hamiltonian MPO. Each 2-qubit tensor has a size bounded by , so the memory of the Krylov vectors used in the Lanczos algorithm reads
where is the value of max_krylov_dim. Recall that the default value of and if the Lanczos algorithm requires more Krylov vectors to converge to the tolerance, it will error, rather than exceed the above bound.
Contribution from temporary tensors
Section titled “Contribution from temporary tensors”Finally, to compute the above Krylov vectors, the effective two-site Hamiltonian has to be applied to the previous Krylov vector to obtain the next one. The resulting tensor network contraction cannot be done in-place, so it has to store two intermediate results that get very large. The intermediate results take the most memory at the center qubit, where the bond dimension of the Hamiltonian becomes , where
It should be noted that the value of cited above assumes that all qubits in the system interact via a two-body term, which is technically true for the Rydberg interaction.
Benchmarking memory footprint
Section titled “Benchmarking memory footprint”Putting all of this together, for the total memory consumption of the program, we can write the following bound:
Note that this estimate is pessimistic, since not all Krylov vectors are likely to be needed, and not all tensors in and the baths have the maximum bond dimension . On the other hand, the estimate for is likely to be accurate, since the bond dimension of is probably attained at the center qubit.
To test the accuracy of the above memory estimations, we run the TDVP time evolution algorithm, fixing the bond dimension to a particular desired value. For different combinations of the number of atoms in a register and the fixed bond dimension , we collect the maximum resident size, or RSS, which is expected to capture the maximum memory needed to run the emulation. We plot the RSS in the following picture (left), as a function of the number of qubits and for different bond dimensions. Notice that, once the RSS is normalized by , as suggested by our estimate above, all the points fall into the same functional dependency on the number of atoms. Moreover, as we plot the normalized function , for a reasonable estimate of the size of the Krylov subspace (), it is clear that our upper bound on memory occupation can be reasonably trusted on a wide range of qubit number and bond dimensions.
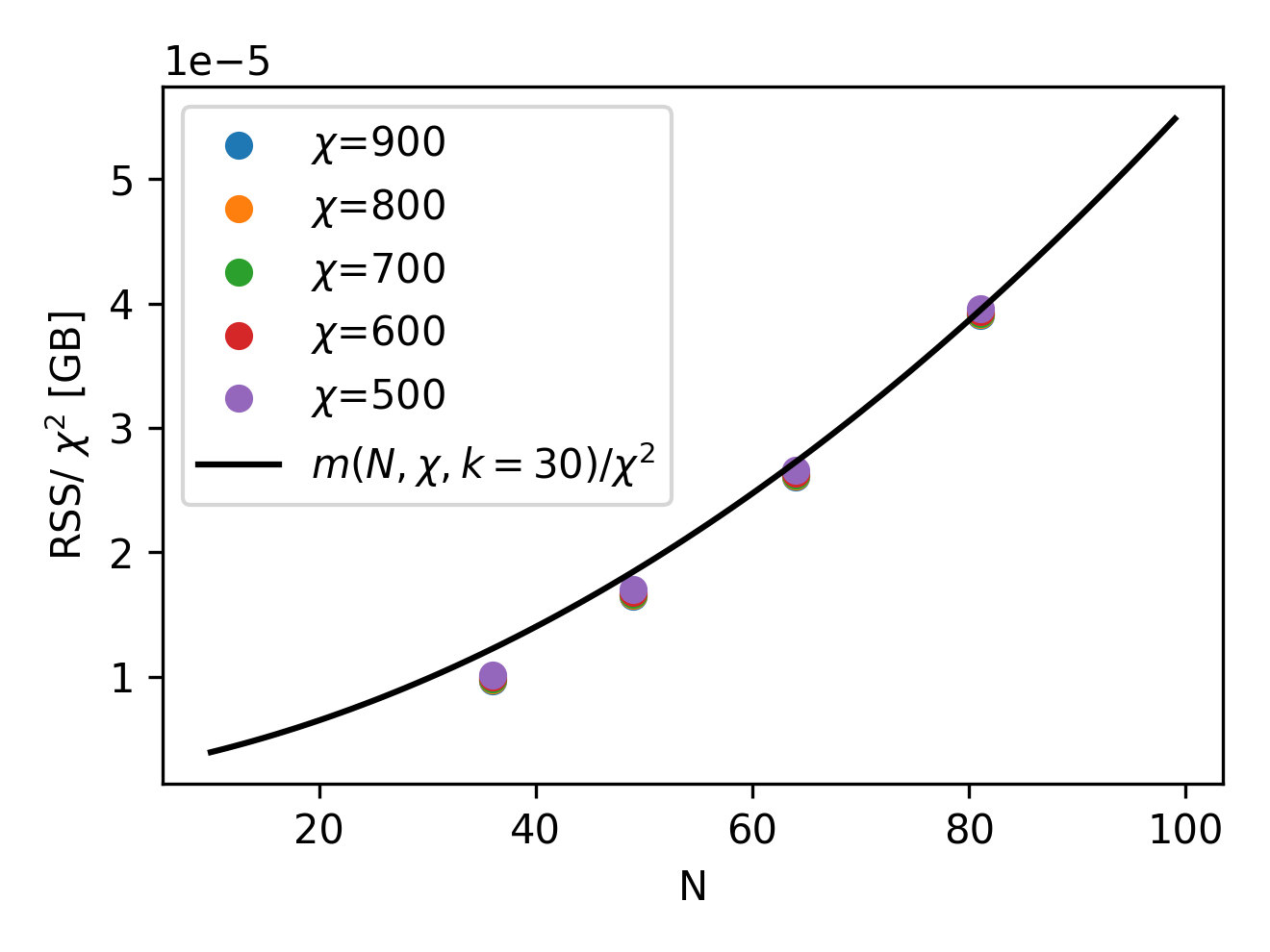
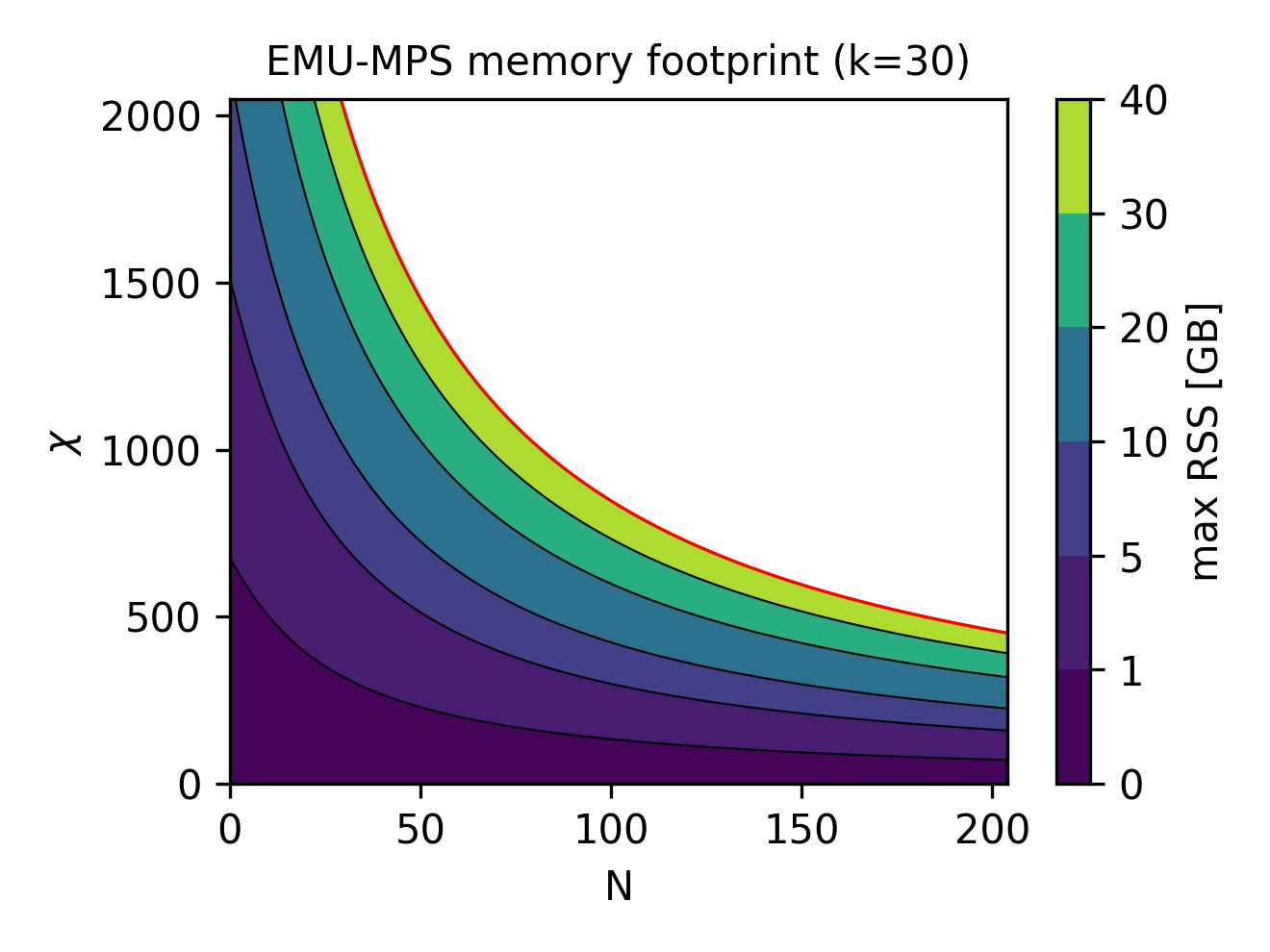
Finally, having established an estimate for the memory consumption, it makes sense to explore what are the available regimes of qubits/bond dimension can be reached for a given hardware capability. Since all heavy simulations will be run on an NVIDIA A100 (on Pasqal's DGX cluster), we have 40 GB of available memory. Therefore, above, we show (right image) the contour lines of the RSS estimate GB for particular useful values of the total memory, allowing to quickly estimate the memory footprint of an emu-mps emulation.
An example
Section titled “An example”For example, the results from the case study were obtained using and on 2 GPUs. Taking the above formula, and halving the contributions from and since they are split evenly on the GPUs, we reproduce the memory consumption of the program for . Notice that the actual number of Krylov vectors required to reach convergence is likely closer to around , but here we underestimate it, since the contributions of and are over-estimated.
Estimating the runtime of a simulation
Section titled “Estimating the runtime of a simulation”Similarly to the previous section, here, we briefly estimate the complexity of the two-site TDVP algorithm we use to time evolve the state in a single pulse sequence step. As before, the two relevant computational steps are
- Computing the baths
- Applying the effective Hamiltonian
In both cases, it will boil down to an exercise in complexity estimation of tensor network contractions. For simplicity, as before, we will restrict to the worst case scenario in which the bond dimension always take the maximum allowed value. Importantly, another significant contribution to the runtime can come from computing complex observables like two-point correlation functions, which is not included here.
Contribution from the baths
Section titled “Contribution from the baths”Roughly, baths computation involves the represented tensor network contraction:

Each of these tensor multiplication takes respectively , , and . In an all-to-all Rydberg interaction, we already argued that the bond dimension of the Hamiltonian MPO should scale as the number of atoms. Moreover, the left and right baths need to be computed roughly N times, thus the overall expected complexity is .
Contribution from the effective Hamiltonian
Section titled “Contribution from the effective Hamiltonian”Applying the effective two-body Hamiltonian is slightly a more involved tensor network contraction:

In steps, it is composed by applying:
- the left bath:
- a two-body term coming form the MPO Hamiltonian:
- the right bath:
As before, for an all-to-all Rydberg interaction we expect . Moreover, the effective Hamiltonian application needs to be done times, to build the appropriate Krylov subspace, and for every pair. Finally, to complete the time evolution and bring back the tensors of the state into an MPS form, a final singular value decomposition is required. For every pair, this requires to be done. Overall, the expected complexity is thus .
Benchmarking runtime
Section titled “Benchmarking runtime”From the previous complexity estimations, we thus expect the complexity of the two-sites TDVP algorithm to have two main contributions
To check such estimation, as before, we run TDVP multiple times, measuring the average runtime to perform a step. Below, we show the obtained results for different number of atoms in a register at fixed bond dimension (left), and at different fixed but increasing the bond dimension (left). On top of these data points, we also plot the resulting fit of the complexity estimation presented in the equation above. Remarkably, with just two parameters and with get good agreement.
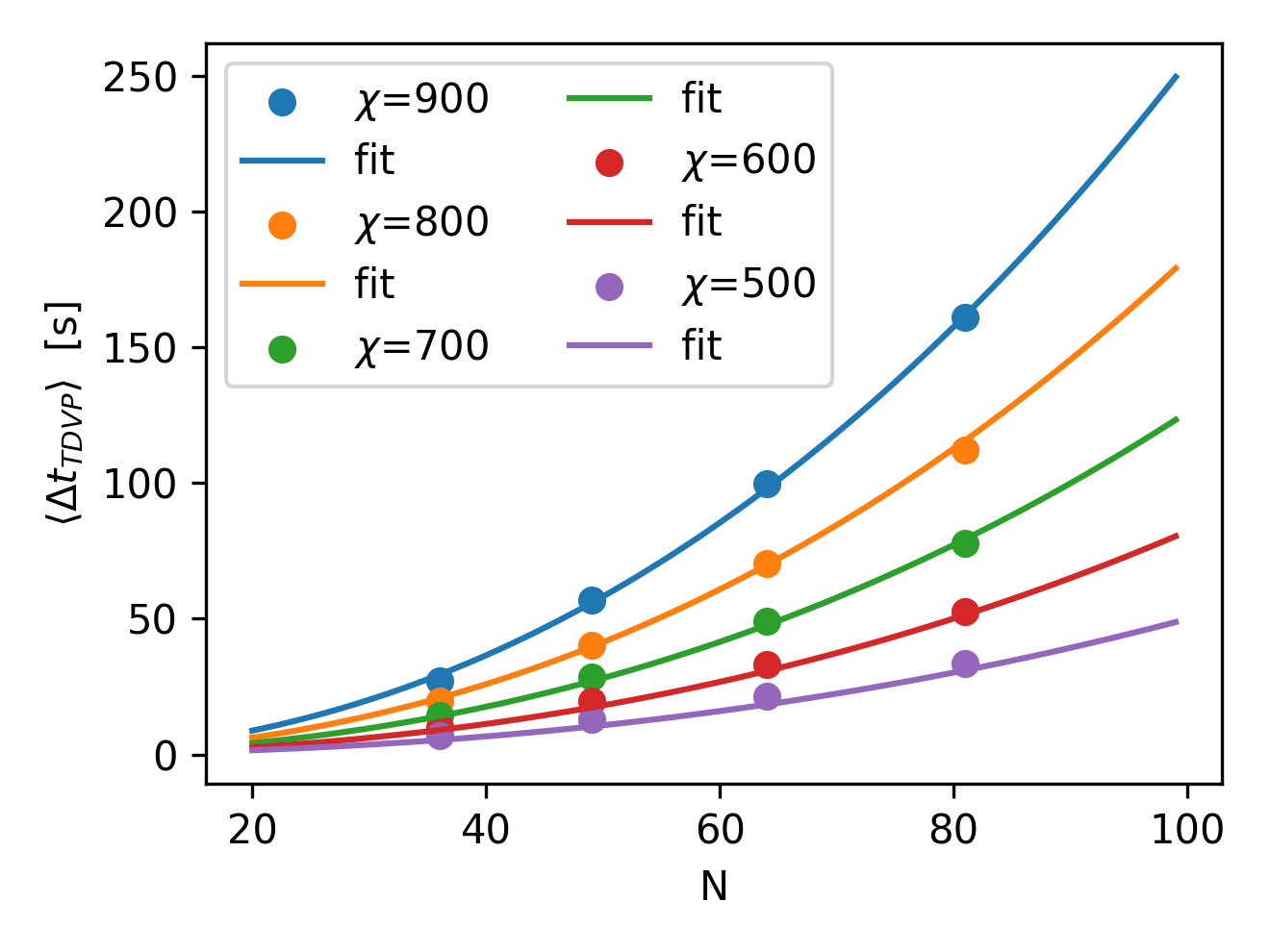
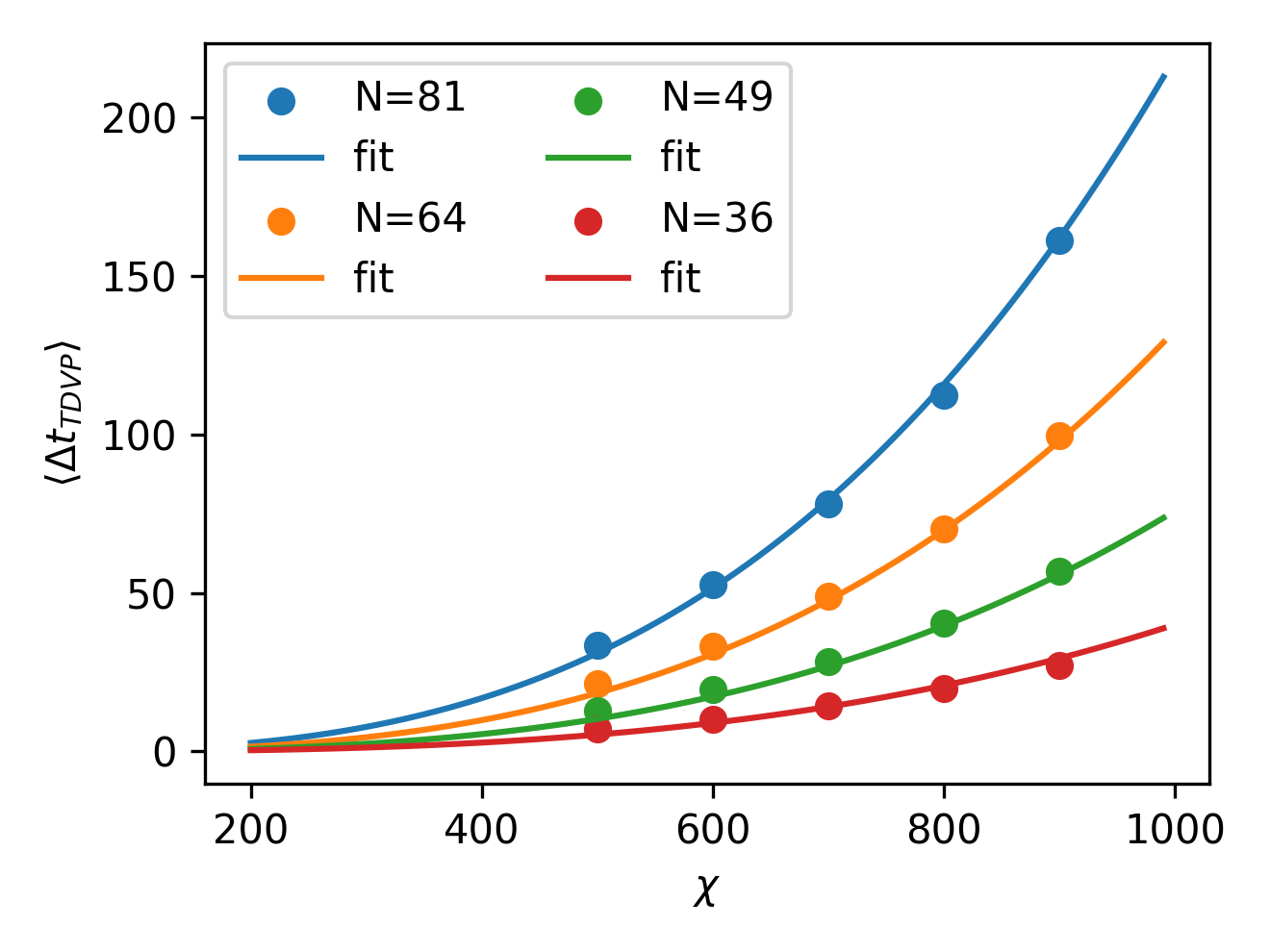
To wrap up, and to provide an useful tool for runtime estimation for emu-mps, the time to perform a single time step in a sequence can be conveniently visualized (below) for both and on contour lines.
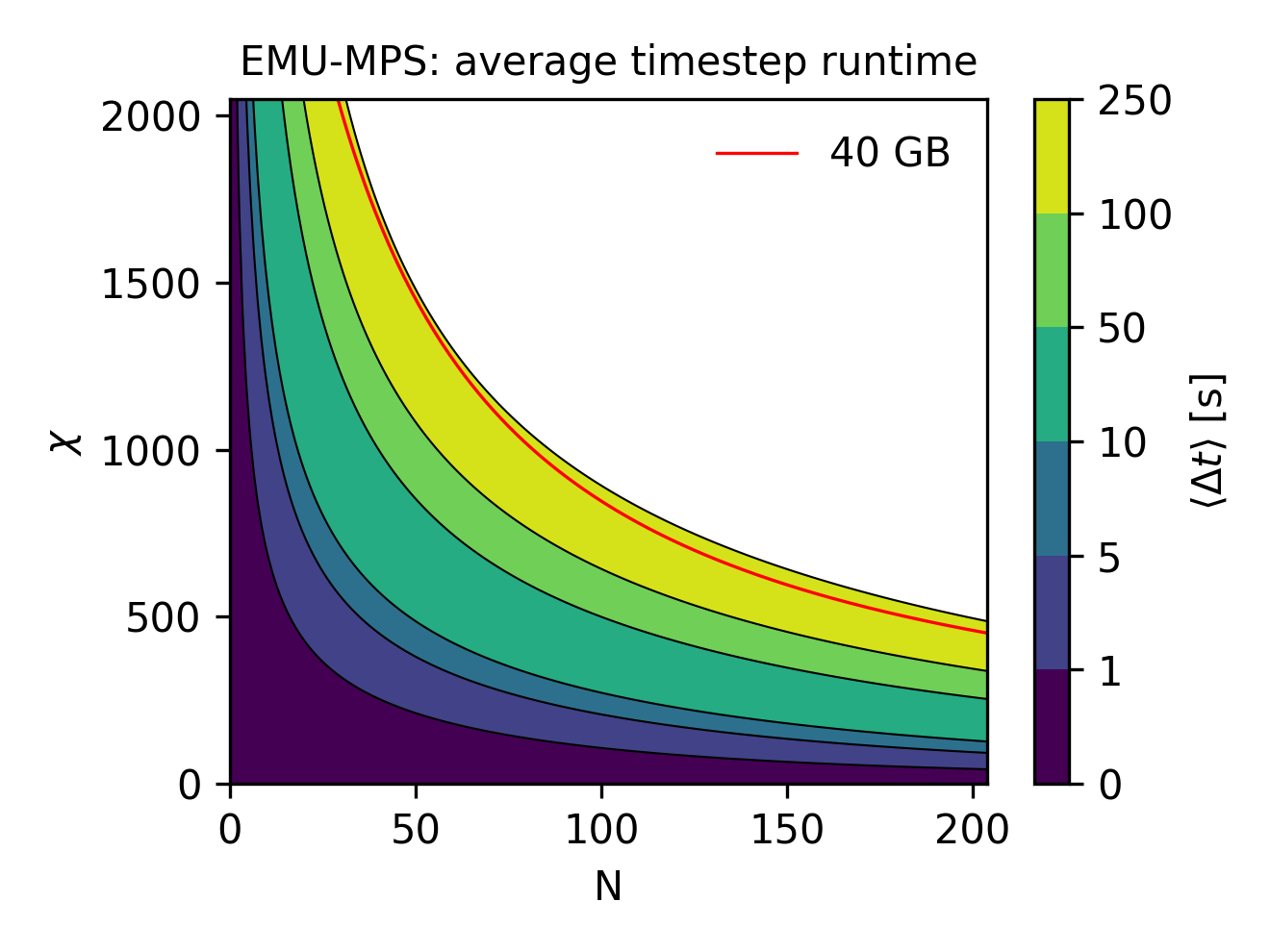
Superimposing the 40 GB hardware constrain derived in the previous section, it is easy to see that in worst-case scenario, a TDVP step will take roughly 250 seconds to be computed.